Introduction
What is PB?
PB stands for Profile Builder. It allows you to transform the data in your warehouse, without writing complex SQL queries! Each PB model represents a transformation which takes an existing table or another model’s output as its input and uses the inputs to create an output table or view. SQL transformations are run within the warehouse while Python transformations may use ML Inference in notebooks running outside the warehouse.
Current app version is v 0.10.4.
Older Versions
How can I use PB?
You can create a PB Project, which can then create ID stitcher or Entity Features using CLI or web app.
CLI
Following is the output of pb showcasing its various functionalities.
$ pb <command> <subcommand> [parameters]
Usage:
pb [command]
Available Commands:
cleanup cleanup materials
compile compile models
discover discover models, sources, entities, features, materials
help Help about any command
init Create an initial pb project
insert load sample data in warehouse
migrate migrate a project schema to the latest version
query run SQL query
run run models
show Show models in the project
validate validate aspects of the project and configuration
version print the version
Flags:
-h, --help help for pb
Use "pb [command] --help" for more information about a command.
PB Project
Models contained in PB Project can be run using the command line tool to create initial projects, run the project, query the warehouse for sample outputs, discover features in the warehouse, etc.
PB Project is a collection of interdependant warehouse transformations. Each transformation is captured in a PB model. Various types of models are supported like ID stitching, entity features, custom models using Python. External transformations in Python are also on the roadmap.
Scheduling via web app
Using the command line tool, you can run PB projects any time you want. However, once your models are stable, you might want to schedule their invocations periodically(eg. everyday, every 12 hours, etc). That can be done by scheduling your PB run tasks on the RudderStack web app.
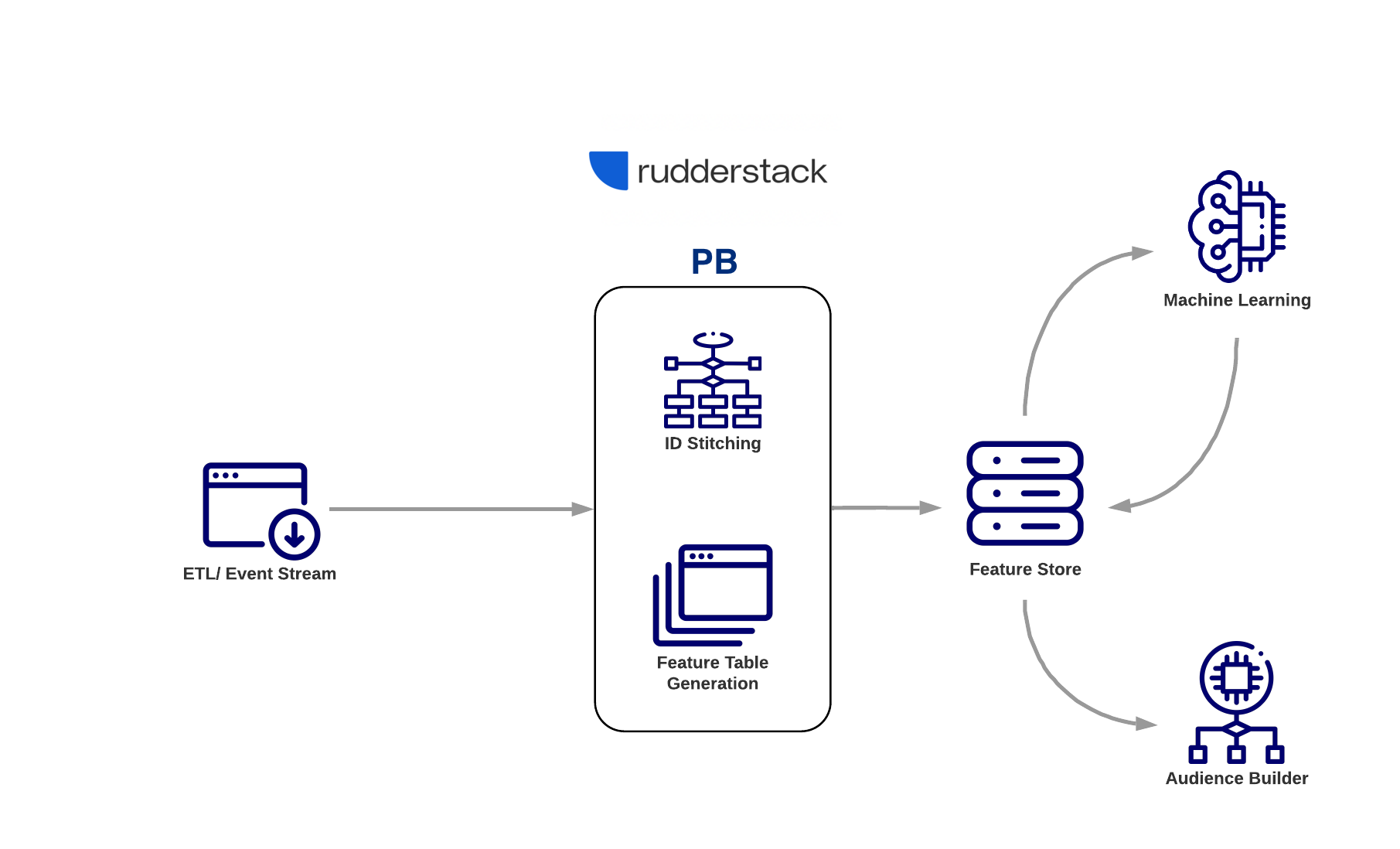
What can I achieve using PB?
ID Stitching
With ID Stitching, you can map the same ID across different platforms. For example, a website has multiple features and 3rd party tools like live chat, google analytics, SalesForce CRM etc. Let’s assume a user is not logged into live chat but is on SalesForce where they interacted with your sales team. After the data from all of these sources is loaded into your warehouse, the ID Stitching feature can tie together all of these different IDs to a single user.
Note
Anonymous ID is when you haven’t logged in, so a random number is generated in the Database. Non-anonymous ID is what is known like an email, phone number etc. So, after a user browses privately and then finally logs in, then PB will stitch that this is same ID. For more details, refer the page Identity Stitching.
Entity Features
Entity Features are generated based on events, user attributes, and other defined criteria.
One can define models that can create entity features reflecting a complete 360 data for users with id stitching, external sources, etc.
Model files are defined in YAML.
Note
Check out RudderStack’s YAML Refresher for a quick guide on base concepts, syntax, and best practices for writing code in YAML.
Materializations
The models described above, when run, will produce materials - that is, tables / views in the database that contain the results of that model run. There are two main run types:
discrete: The model result is calculated from it’s inputs whenever run (the default)
incremental: In this mode, model run reads updates from input sources and result from previous run. This makes incremental runs efficient. A good example is ID Stitcher, which builds upon graph from its previous run by incorporating recent data.
Data Sources
You can transform data from these sources:
Rudder EventStreams: These are loaded from Events.
ETL Extract: They are loaded from Cloud Extract.
External Tables: Your existing tables on the Warehouse, generated by other tools.
Supported Warehouses
Right now, we are supporting Snowflake, Redshift and Databricks, with more data warehouses in the pipeline.
Contact Us
In case you’re facing any issues with PB or want to talk to our team, feel free to contact us.