Entity Traits 360
You may have variety of data about your customers or other entities in your warehouse. This document details how you can extract various features from all the data in your warehouse via RudderStack.
PB entity features is envisioned to have all the computed traits you want to have derived from your warehouse data tables. Each column in the table gives a trait for an entity.
Some of the advantages of using the PB YAML to generate the entity features view:
Identity Stitching is done behind the scenes. Output of ID stitcher is incorporated transparently.
Hides the complexity of the query execution plan from business logic, making it easier to maintain. Especially, as the number of entity features increase.
Generates performant SQL using well researched SQL idioms. As the feature table becomes wider, dependencies become deeper and feature sources come from many teams.
Designed to meaningfully reflect the SQL that you want to generate by abstracting out query complexity. If you have some experience with SQL, its easy to understand how to define the YAML for desired traits. This document will walk you through details how you can define your project YAML file(s).
Now that you have a unified user trait table(s), below are some possible ways you can use:
Build various models like churn prediction (RudderStack ML models can be used for this).
Analytics queries like demographic view, user activity view etc.
Activate this data using RudderStack ReverseETL to send to various cloud destinations [Doc].
Build and use RudderStack Audiences (available for beta customers).
Creating Entity Features
A basic structure of any entity feature YAML would look like this:
var_groups:
- name: <string>
entity_key: <string>
vars: [entity_vars, input_vars]
Each feature is defined by using entity_var. Vars are grouped under var_groups, so that some config keys can be shared across vars.
Example Entity Feature YAML:
var_groups:
- name: default_vars
entity_key: user
vars:
# Latest Country
- entity_var:
name: max_timestamp_for_country
select: max(timestamp)
from: inputs/identifies_1
where: properties_country is not null and properties_country != ''
is_feature: false
- entity_var:
name: latest_country
select: max(properties_country)
from: inputs/identifies_1
where: timestamp = max_timestamp_for_country and main_id is not null
# If you have more granular demographic data, then you can get more accurate
# information about the customer in the similar manner using feature YAML.
# Active Time
- entity_var:
name: first_active
select: min(timestamp)
from: inputs/identifies_1
is_feature: false
- entity_var:
name: last_active
select: max(timestamp)
from: inputs/identifies_1
is_feature: false
- entity_var:
name: active_days
select: "{{ subtract_range('last_active', 'first_active')}}"
# subtract_range is a macro, defined below in a separate YAML file
This will create an entity var table. As shown below, this table brings together all features defined, across all vars in var_groups.
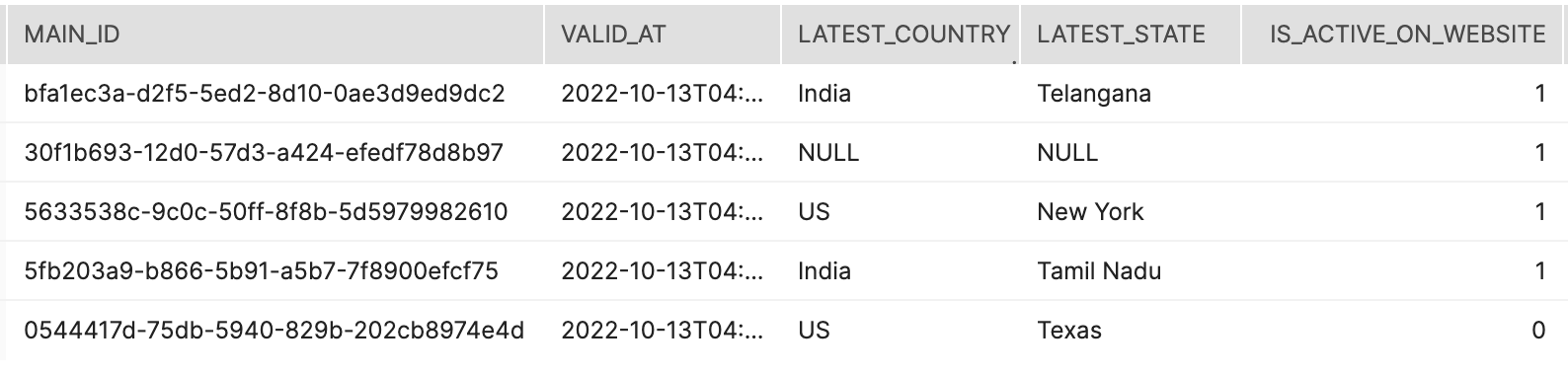
Var groups
type |
object |
|
properties |
||
|
Name of var_group, that will be used to uniquely identify it. |
|
type |
string |
|
|
Specify the entity to be used. |
|
type |
time |
|
|
This section is used to specify variables, with the help of entity_var and input_var. Aggregation on stitched ID type is done by default and is implicit. |
|
type |
list |
|
entity_var
This is a special type of variable that can be used to store some data temporarily. To store data permanently, they can be specified as a ‘feature’ in the next key. While creating this, grouping on main ID type of your ID Stitcher model is done by default. |
|||
properties |
|||
|
Name of the entity_var, this will be used to uniquely identify it. |
||
type |
string |
||
|
The column name/value you want to select from the table. This defines the actual value that will be stored in the variable. You can use simple SQL expressions as well here. You can also select an entity var as {{entityName.Var(“entity_var”)}}. It has to be an aggregate operation that ensures the output is a unique value for a given main_id. Ex: min(timestamp), count(*), sum(amount) etc. This holds true even when a window function (optional) is used. Ex: first_value(), last_value() etc are valid while rank(), row_number() etc are not valid and give unpredictable results. |
||
type |
string |
||
|
Here you have to specify the info of the table to be used. You can either refer to another model from the same YAML or some other table specified in input YAML. |
||
type |
list |
||
|
Any filters you want to apply on the input table before selecting any value. This needs to be SQL compatible and must be respecting the data type of the table. |
||
type |
string |
||
|
The default value that needs to be stored in case no data matches the filter. |
||
type |
string |
||
|
Description of the entity_var, and it is always good to have a good description for your entity_var. This helps in understanding the logic without overhead of understanding the value SQL. |
||
type |
string |
||
|
Whether the entity_var is a feature. By default it is set to true. |
||
type |
boolean |
||
|
If you want to use window function, that needs to be specified with the help of this key. Window function usually operates over a window of rows so we need a subgroup of rows for this to work. Apart from some rank-related functions, the rows in window need at-least one column in it. Window functions in SQL usually have both partition by and order by properties. But for entity_var, partition_by is added with main_id as default; So, adding partition_by manually is not supported here. If you need partitioning on other columns too, check out input_vars where partition_by on arbitrary and multiple columns is supported. |
||
type |
object |
||
properties |
|||
|
This orders rows within the window. |
||
type |
string |
||
Note
As this does a group by main_id, the output would be one row per main_id.
input_var
With syntax almost identical to entity_var, the difference is that instead of each value being associated a row of the feature table, it’s associated with a row of the specified input. Effectively, while a entity_var can be thought of as adding a helper column to the feature table, an input_var can be thought of as adding a helper column to the input. |
|||
properties |
|||
|
This is the name in which you’ll store the retrieved data. |
||
type |
string |
||
|
The data that will be stored in the |
||
type |
string |
||
|
A reference to the source table from which data is to be fetched. |
||
type |
list |
||
|
Optional, in case you want to apply any conditions for fetching data (same as where clause in SQL). |
||
type |
string |
||
|
Optional, a default value for any entities for which the calculated value would otherwise be NULL. |
||
type |
string |
||
|
Optional, a textual description of what it does. |
||
type |
string |
||
|
Optional, for specifying a window over which the value should be calculated. |
||
type |
object |
||
properties |
|||
|
Optional, list of sql expressions to use in partitioning the data. |
||
type |
string |
||
|
Optional, list of sql expressions to use in ordering the data. |
||
type |
string |
||
Note
In window option, main_id is not added by default unlike tablevar; it can be any arbitrary list of columns from the input table. So if a feature should be partitioned by main_id, that should be added with the partition_by key.
Warning
If an entity_var is expected to be derived from more than one input_var - then all the input_var need to be on the same table.
Note
There won’t be any group by main_id operator in this, and it is used only to apply some transformations on already calculated tablevars/featurevars.
Default values
When defining default values for an entity_var or input_var, enclose string values in single quotes followed by double quotes to avoid SQL failure. Non-string values can be used without quotes. For example:
entity_var:
name: campaign_source_first_touch
default: "'organic'"
entity_var:
name: user_rank
default: -1
Window Functions
In PB, Profiles YAML have support to use window functions in entity var and input var definitions.
What is a window function: A window function operates on a group (“window”) of related rows. Each time a window function is called, it is passed a row (the current row in the window) and the window of rows that contain the current row. The window function returns one output row for each input row. The values returned are calculated by using values from the sets of rows in that window. For each row in the table, the window defines a set of rows that is used to compute additional attributes. A window is defined using a window specification (the OVER clause), and is based on three main concepts:
Window partitioning, which forms groups of rows (
PARTITIONclause)Window ordering, which defines an order or sequence of rows within each partition (
ORDER BYclause)Window frames, which are defined relative to each row to further restrict the set of rows (
ROWSspecification)
We already had the support of specifying PARTITION and ORDER BY while using the window function to write the features in YAML. Now we can specify the ROWS as well which is known as frame clause.
Most of the warehouses supports two types of window functions: aggregate and ranking.
Why this is important:
Snowflake does not enforce user to define the cumulative or sliding frames, and it considers ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING as default cumulative window frame. But user can override this by defining the frame manually as well.
But on the other hand, in Redshift if an ORDER BY clause is used for an aggregate function, an explicit frame clause is required but if a ranking window functions is specified then frame clause should not be specified.
So if there is any use of window function then we have to be aware of using frame_clause . It is not very critical for Snowflake but it is very critical for Redshift as this will result in errors.
On Redshift aggregate window function, list given below, while using any function from the list, please specify the frame_clause:
AVG
COUNT
CUME_DIST
DENSE_RANK
FIRST_VALUE
LAG
LAST_VALUE
LEAD
LISTAGG
MAX
MEDIAN
MIN
NTH_VALUE
PERCENTILE_CONT
PERCENTILE_DISC
RATIO_TO_REPORT
STDDEV_POP
STDDEV_SAMP (synonym for STDDEV)
SUM
VAR_POP
VAR_SAMP (synonym for VARIANCE)
On Redshift ranking window functions given below, while using any function from the list, please DO NOT specify the frame_clause:
DENSE_RANK
NTILE
PERCENT_RANK
RANK
ROW_NUMBER
How to specify frame_clause:
- entity_var:
name: first_num_b_order_num_b
select: first_value(tbl_c.num_b)
from: inputs/tbl_c
default: -1
where: tbl_c.num_b >= 10
window:
order_by:
- tbl_c.num_b desc
frame_clause: ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
- entity_var:
name: first_num_b_order_num_b_rank
select: rank()
window:
partition_by:
- first_num_b_order_num_b > 0
order_by:
- first_num_b_order_num_b asc
Please pay attention how frame_clause is specified in first entity_var and not in the second one.
Defining ML Features
PythonML
More information on ProfilesML at RudderStack Docs.
Models from ML Notebooks
You can take ML Notebooks in Jupyter and add ML/AI capabilities to it.
Complete Traits 360 degree view
Traits defined using entity_vars and ML models can all be unified using traits360 models. The corresponding entries are made in pb_project.yaml. Please check out the section Entity Traits 360 Models for details.
Feature Table (legacy / deprecated)
PB Entity Feature YAML allows you to define what traits needs to be evaluated from provided data sources to create and keep feature table(s) updated. The section on Identity Stitching detailed how you can leverage RudderStack to do ID stitching to identify your users. Each identified user now can have multiple traits that you want to evaluate and maintain.
Basic things to have before starting up with the feature YAML:
name: This is going to be used in the naming of final feature table in warehouse. For example if name isWACampaignFeaturesthen the name of the feature table and final view in the warehouse will beMaterial_WACampaignFeatures_<some_hash>.model_type: should befeature_table_model.
A basic structure of any feature YAML would look like this:
models:
- name: <string>
model_type: feature_table_model
model_spec:
validity_time: <time>
entity_key: <string>
features: <list>
Example:
models:
- name: e_comm_feature
model_type: feature_table_model
model_spec:
validity_time: 24h # 1 day
entity_key: user
features:
- latest_country
- active_days
model_spec:
Here you have to give all the specifications for your expected model type.
In the case of feature_table_model the specifications are as follows:
name
Name of the feature table created on the DW. Say if you define this as then the output table will be named something like
|
|
type |
string |
model_type
Define the types of models. As we are creating a Feature Table, set this to |
|
type |
string |
model_spec
Here you have to give all the specifications for your expected model type. In the case of |
||
type: list |
||
properties |
||
|
This specifies the validity of generated feature table. Once the validity is expired, scheduling takes care of generating new tables. for example: 24h for 24 hours, 30m for 30 minutes, 3d for 3 days |
|
type |
time |
|
|
Here you have to give the reference of entity to be used. An entity can either refer to another ID stitcher model specified in the same project or an ID stitcher model from same YAML. |
|
type |
string |
|
|
This section is used to specify list of``entity_var``, that act as a feature. An entity_var is by default defined as a feature. |
|
type |
list |
|
Defining Macros (optional)
Example Macros YAML:
macros:
- name: subtract_range
inputs:
- a
- b
value: "{{a}} - {{b}}"
macros
Here you can specify the macros that can be used later in Macros can be used to encapsulate complex processing logic directly within SQL that can be reused. You can consider these as functions. |
||
type: list |
||
properties |
||
|
Name of macro, this will be used to uniquely identify and reference this macro in |
|
type |
string |
|
|
If the logic you are trying to encapsulate works on some input variable, then you need to define those here. |
|
type |
list |
|
|
Actual logic, this must be a SQL expression. Any reference to the inputs within it should be surrounded by double curly brackets. |
|
type |
string |
|
Feature Table Code Examples
Please contact our team for access to example projects.